Simple Question
What is spark?
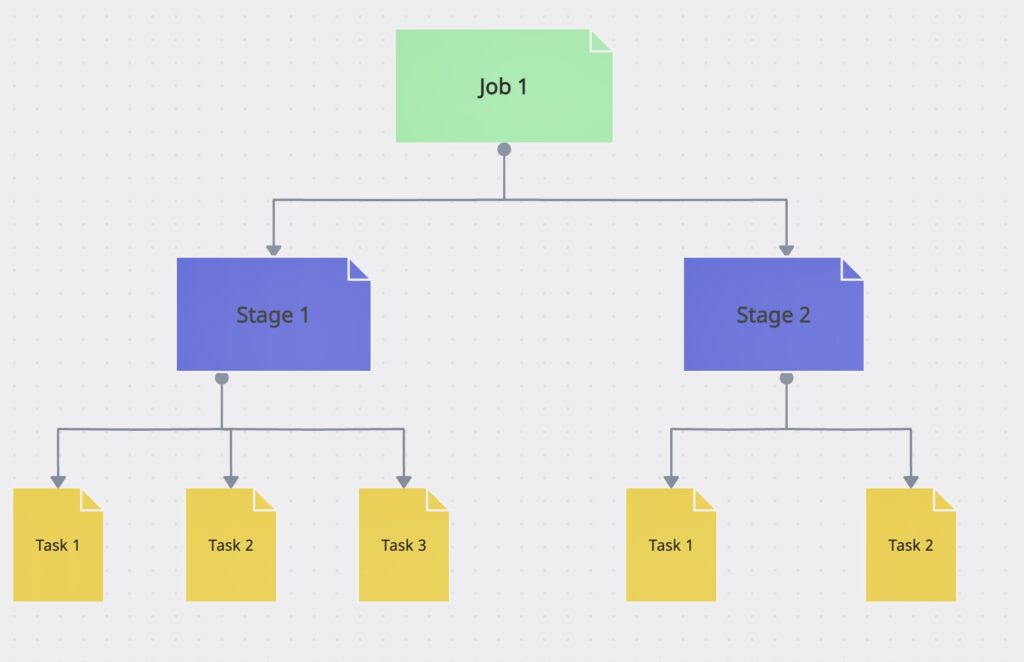
What is stage, with regards to Spark Job execution?
Ans: A stage is a set of parallel tasks, one per partition of an RDD, that compute partial results of a function executed as part of a Spark job.
What is Task, with regards to Spark Job execution?
Ans: Task is an individual unit of work for executors to run. It is an individual unit of physical execution (computation) that runs on a single machine for parts of your Spark application on a data. All tasks in a stage should be completed before moving on to another stage.
What are the workers?
Ans: Workers or slaves are running Spark instances where executors live to execute tasks. They are the compute nodes in Spark. A worker receives serialized/marshalled tasks that it runs in a thread pool.
How do you define actions?
Ans: An action is an operation that triggers execution of RDD transformations and returns a value (to a Spark driver – the user program). They trigger execution of RDD transformations to return values. Simply put, an action evaluates the RDD lineage graph.
You can think of actions as a valve and until no action is fired, the data to be processed is not even in the pipes, i.e. transformations. Only actions can materialize the entire processing pipeline with real data.
What is Narrow Transformations?
Ans: Narrow transformations are the result of map, filter and such that is from the data from a single partition only, i.e. it is self-sustained.
An output RDD has partitions with records that originate from a single partition in the parent RDD. Only a limited subset of partitions used to calculate the result. Spark groups narrow transformations as a stage.
What is wide Transformations?
Ans: Wide transformations are the result of groupByKey and reduceByKey . The data required to compute the records in a single partition may reside in many partitions of the parent RDD.
All of the tuples with the same key must end up in the same partition, processed by the same task. To satisfy these operations, Spark must execute RDD shuffle, which transfers data across cluster and results in a new stage with a new set of partitions.
What is a lazy evaluation in Spark?
Ans: When Spark operates on any dataset, it remembers the instructions.When a transformation such as a map() is called on an RDD, the operation is not performed instantly. Transformations in Spark are not evaluated until you perform an action, which aids in optimizing the overall data processing workflow, known as lazy evaluation.
What is Shuffling?
Ans: Shuffling is a process of repartitioning (redistributing) data across partitions and may cause moving it across JVMs or even network when it is redistributed among executors. Avoid shuffling at all cost. Think about ways to leverage existing partitions. Leverage partial aggregation to reduce data transfer.
Medium Question
How DAG functions in Spark?
Ans: At the point when an Action is approached Spark RDD at an abnormal state, Spark presents the heredity chart to the DAG Scheduler.
Activities are separated into phases of the errand in the DAG Scheduler. A phase contains errands dependent on the parcel of the info information. The DAG scheduler pipelines administrators together. It dispatches tasks through the group chief. The conditions of stages are obscure to the errand scheduler.The Workers execute the undertaking on the slave.
What is Data locality / placement?
Ans: Spark relies on data locality or data placement or proximity to data source, that makes Spark jobs sensitive to where the data is located. It is therefore important to have Spark running on Hadoop YARN cluster if the data comes from HDFS.
With HDFS the Spark driver contacts NameNode about the DataNodes (ideally local) containing the various blocks of a file or directory as well as their locations (represented as InputSplits ), ad the shedules the ork to the “parkWorkers. “park’s opute odes / orkers should e running on storage nodes.
What is a Broadcast Variable?
Ans: Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks.
How can you define Spark Accumulators?
Ans: This are similar to counters in Hadoop MapReduce framework, which gives information regarding completion of tasks, or how much data is processed etc.
What are the different levels of persistence in Spark?
Ans: ∙ DISK_ONLY – Stores the RDD partitions only on the disk
∙ MEMORY_ONLY_SER – Stores the RDD as serialized Java objects with one-byte array per partition
∙ MEMORY_ONLY – Stores the RDD as deserialized Java objects in the JVM. If the RDD is not able to fit in the memory available, some partitions won‟t be cached
∙ OFF_HEAP – Works like MEMORY_ONLY_SER but stores the data in off-heap memory
∙ MEMORY_AND_DISK – Stores RDD as deserialized Java objects in the JVM. In case the RDD is not able to fit in the memory, additional partitions are stored on the disk
∙ MEMORY_AND_DISK_SER – Identical to MEMORY_ONLY_SER with the exception of storing partitions not able to fit in the memory to the disk
What is the difference between map and flatMap transformation in Spark
| map | flatMap |
| It is used for 1 input row and return 1 output | It used for 1 input row and return 0 to n output |
| Example: upper, | split function in word count job |
Difference between reduce() vs reduceByKey().
| reduce() | reduceByKey() |
| It is a action. | It is a transformation. |
| Used for final output. | It is a intermediate result. |
How is Apache Spark different from MapReduce?
| Apache Spark | MapReduce |
| Used for batch and steam processing. | Only batch processing. |
| Running 10 to 100 times faster than MapReduce. | Slower than Spark. |
| Stores intermediate data in the RAM i.e. in-memory. So, it is easier to retrieve it. | Hadoop MapReduce data is stored in HDFS and hen longer time to retrieve the data |
| Provides caching and in-memory data storage | No caching, depend on disk only. |
How to get to know number of partition in RDD?
RDD have the getNumPartitions() to know the number of partition.
df1.rdd.getNumPartitions()How to get to know number of partition in DataFrame?
There is no direct method in DataFrame to know the number of partition. First convert DataFrame to RDD.
df1.rdd.getNumPartitions()Hard Question
Confusing Interview Question in Spark
Difference between Left join and Left outer join.
Ans: Both are same, there is no difference between them.
Difference between Union and UnionAll in Spark.
Ans: There is no difference in union and union all in Spark. for more Check Union vs UnionAll in Spark .
Difference between distinct() vs dropDuplicate() without any parameter.
Ans. There is no difference in distinct and dropDuplicate() without any parameter.If there is list of column provide like dropDuplicate([‘id’]), then it’s drop the rows duplicate id only.